How to Leverage ZKPs as a Web3 Builder

Mohamed Fouda
·Mar 22, 2023
By Mohamed Fouda and Qiao Wang

Zero-knowledge proofs (ZKPs) are shaping out to be a fundamentally transformative technology for the next decade. ZKPs are finding applications within and outside Web 3. In Web 3, the technology is already addressing major bottlenecks in scalability and privacy; two major pain points in exciting blockchains. On the scalability front, several zk rollups, aka validity rollups, are launching to scale Ethereum by 10–100x while improving UX by reducing transaction costs. On privacy, ZKPs are expanding beyond private transactions and transaction mixing era into more complex and useful areas such as private on-chain trading, identity, and verified credentials.
There is a lot of content on ZKPs including our own vision of how the ZKP space will evolve in the future and what startups are needed for this future to materialize. However, there is still a gap in builder education on how to benefit from ZKPs and where to start. This article strives to fill this gap by aggregating important resources to guide developers to understand how ZKPs work in practice and how to use ZKPs in their applications.
At Alliance, we are particularly excited about the new use cases enabled by ZKPs. We encourage builders in this space to reach out to discuss their ideas and apply to the Alliance program.
How ZKPs work in practice
The standard definition of ZKPs is that it’s a process for a party, called the prover, to prove to another party, the verifier, that they know specific information without revealing it. In practice, at least in Web 3, ZKPs are often used differently. Most applications don’t use ZKPs to show ownership of proprietary data. Instead, ZKPs are used to improve trust though verifiability. We expect ZKPs to be the standard trust model between entities in the future. The reason is that the two main components of ZKPs, proving and verification, are separated in a way that enables a unique interaction scheme between a trust-seeking entity and its users.
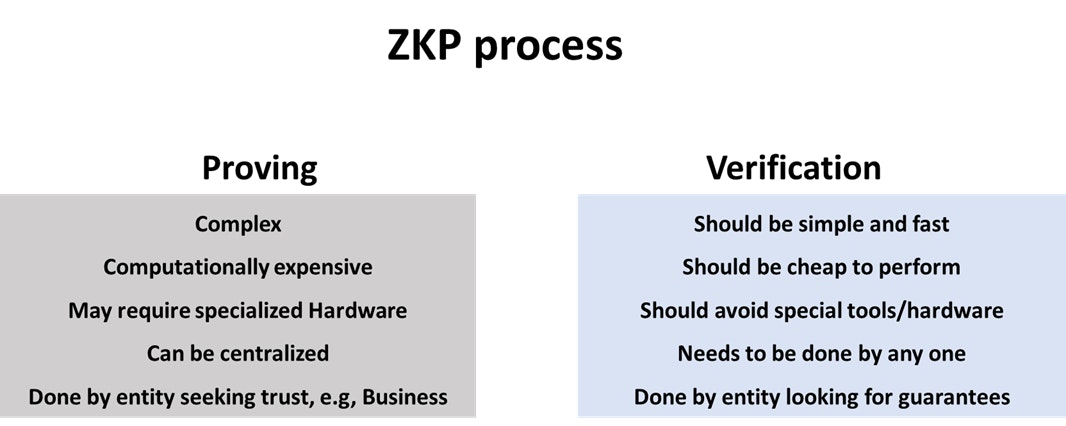
The main components of running ZKP are proof generation and proof verification. Proof generation involves running heavy computations to generate a proof of executing a process. This proof serves to eliminate the need to trust the prover. Instead, anyone can run a simple process on the proof to verify the integrity of the process run by the prover. This mental model allows a business to run a process, often a complicated one and allows the customers to trust the execution of said process without repeating it. Let’s consider an example. Let’s say you subscribed to OpenAI’s paid plans to use one of their large language models (LLMs) such as chatGPT. You have to trust OpenAI to indeed run the specific model that you requested and not replace it with a simpler less-efficient model. What if OpenAI can send you a small amount of data that proves that it has indeed run the specific model you requested? Further, imagine if every proprietary SaaS product can deliver such a guarantee for its consumers.
This trust minimization is the promise of ZKPs. For instance, in Web 2 ZKPs can guarantee fair credit worthiness evaluation or fair insurance claim processing just by insuring that the same algorithm is used for all customers. The zk tech is not there yet as running a ZKP process is still relatively expensive. However, we are seeing companies such as Modulus Labs building a technology that uses ZKPs to prove AI inference.
Technical requirements for efficient ZKPs
On a technical level, an efficient ZKP system requires achieving the following goals simultaneously:
- Reducing the computational complexity and latency of the proving system, i.e., enabling the prover to generate the proofs efficiently and communicate them to the verifiers with minimal delay.
- Achieving a small proof size
- Achieving efficient verification, i.e., minimal verification cost
In addition to these main goals, some secondary goals may be needed depending on the use case such as:
- Privacy of data in privacy-focused applications which means that the proving system can handle private inputs that are not leaked in the generated proof.
- Avoiding trusted setups whenever possible to simplify security assumptions
- Achieving proof recursion to further reduce verification cost, i.e., a single verification can verify multiple proofs, and amortize the cost between different proofs.
It’s challenging to achieve all these goals simultaneously. Depending on the use case, ZKP systems prioritize some of these goals. For instance, SNARK proving systems can produce succinct proofs but the proving complexity increases. STRAKs, on the other hand, have efficient provers but the proof size can be 100x bigger than SNARKs. zk researchers continuously strive to advance the forefront of the technology and improve the three metrics simultaneously by inventing new proving mechanisms.
Comparison of different proving systems
An important question to consider for developers building ZKP-related products is how to select the underlying proving system. There are several ZKP prover implementations, with more in the R&D phase. The ZKP backend selection doesn’t only depend on technical aspects but also depends on the target product. Take as an example selecting a proving system for rollups. The key features of the rollup, e.g., withdrawal time, transaction costs, and even decentralization, will be mainly decided by the ZKP proving architecture as discussed in the following table.
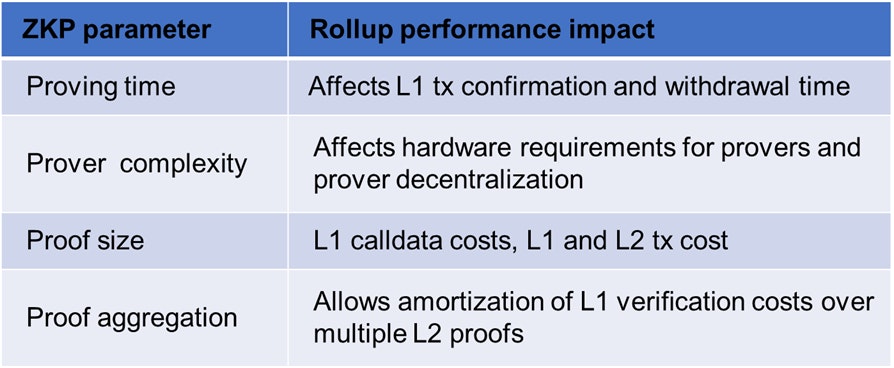
How proving system characteristics affect the performance of ZKP rollup
In rollups, the proving occurs on the business side, i.e., by the rollup operator. Existing zk rollups (zkRUs), e.g., Starknet and zksync currently use centralized provers. Hence, they can delegate the proving to specialized provers, i.e., proving-as-a-service companies, to improve the prover performance. With specialization and utilizing optimized SW/HW, proving time can be reduced to a few minutes for Ethereum-compatible zkEVMs. For instance, the proving time for Polygon zkEVM is currently around 2 minutes. A few minutes of proving time, i.e., withdrawal delay, is acceptable for a rollup.
On the other hand, some use cases require the proving to happen on the user side, e.g., generating private transactions such as Tornado Cash transactions. To ensure a reasonable user experience, the proving time cannot exceed a few seconds. Further, with users performing these computations in the browser on using a wallet on resource-limited devices, it’s important to select a proving system that has a fast prover. A good example here is Zcash’s change of its proving system to Groth16 in the Sapling upgrade in 2018 which was a major factor in improving the speed of shielded transactions by an order of magnitude.
Comparing proving systems
Generally, it’s hard to obtain an accurate comparison of the performance of different proving systems especially for proving and verification speed because they depend on the library implementation, selected cryptographic curves, and the used hardware. The Mina team has provided a good high-level comparison in this article. There are also efforts to create benchmarking tools for different zk systems.
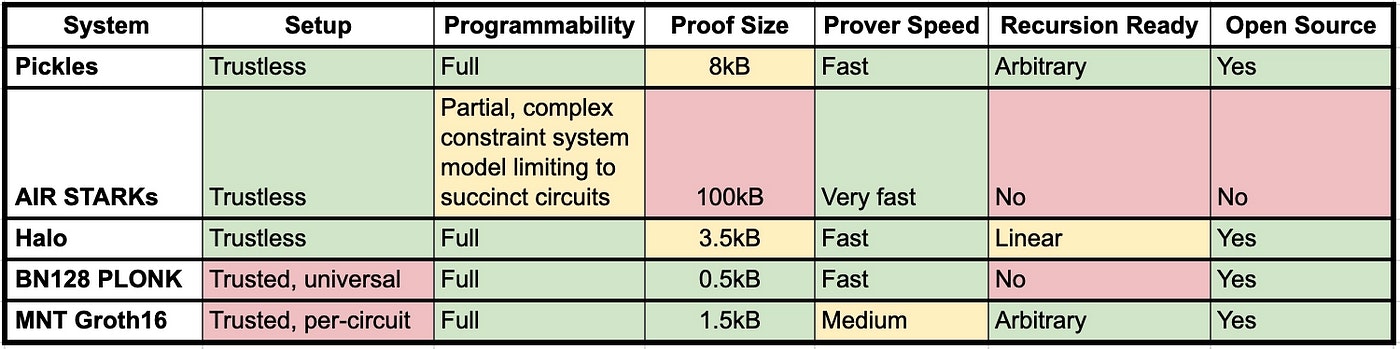
Performance comparison of major proving techniques. Source: O(1) Labs
The table provides a good comparison of SNARK implementations and how they progressed from Groth16 to Plonk to Halo in terms of speed. Despite the progress, STARKs still win on the proving speed front with the cost of larger proof size. The table also discusses two important characteristics of proving systems: setup trustlessness and circuit programmability.
The setup trustlessness part discusses the preprocessing phase of the circuit creation. Some proving techniques require the generation of secret randomness in the preprocessing phase through the participation of multiple entities, i.e, multi-party computation. If a single participant is honest, then the generated randomness is indeed secret and the preprocessing part is secure. This process is called “Trusted Setup” as it trusts that at least one participant in the preprocessing phase is honest. Requiring a trusted setup is considered a weakness. In this sense, STARKs and new SNARK systems such as Halo 2 have an advantage. However, some projects use the Trusted Setup as a tool for engaging the community which was the case for Aztec and Manta.
The programmability part discusses whether the proving system can prove arbitrary computations. SNARKs are generally programmable to any computation. However, proving efficiency depends on the type of computations being performed. This is not the case for some types of STARK systems that are harder to adapt to different kinds of computations.
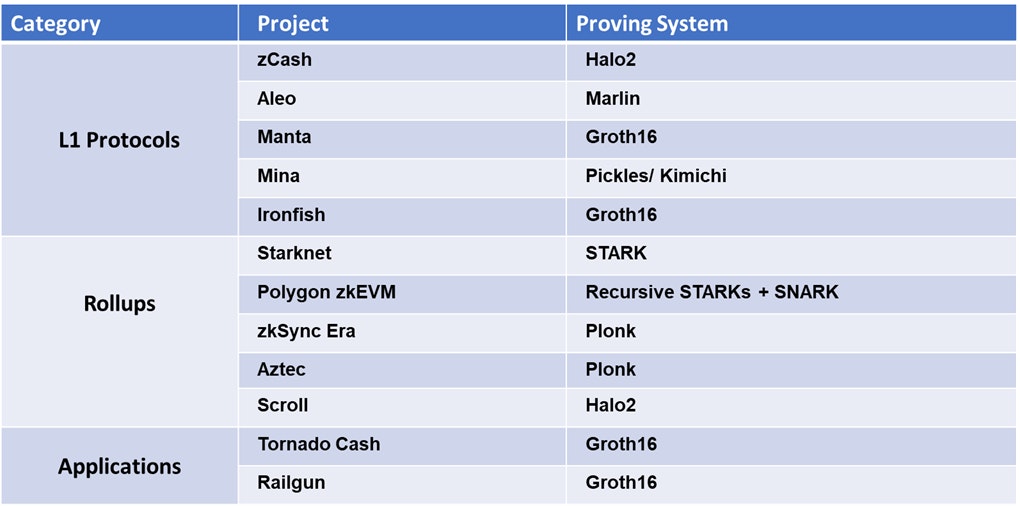
The proving system used for different ZKP-related projects
How to leverage ZKPs for your product
It’s hard to build a mental model on where to start to build a product that benefits from this innovative technology. This section tries to provide a framework for developers to select the best approach to integrate ZKPs in their product. Based on product needs, ecosystem alignment, and performance requirements developers will have several tools to choose from. Some developers will be able to reuse their existing code while others will have to learn new domain-specific languages (DSLs) to create their applications.
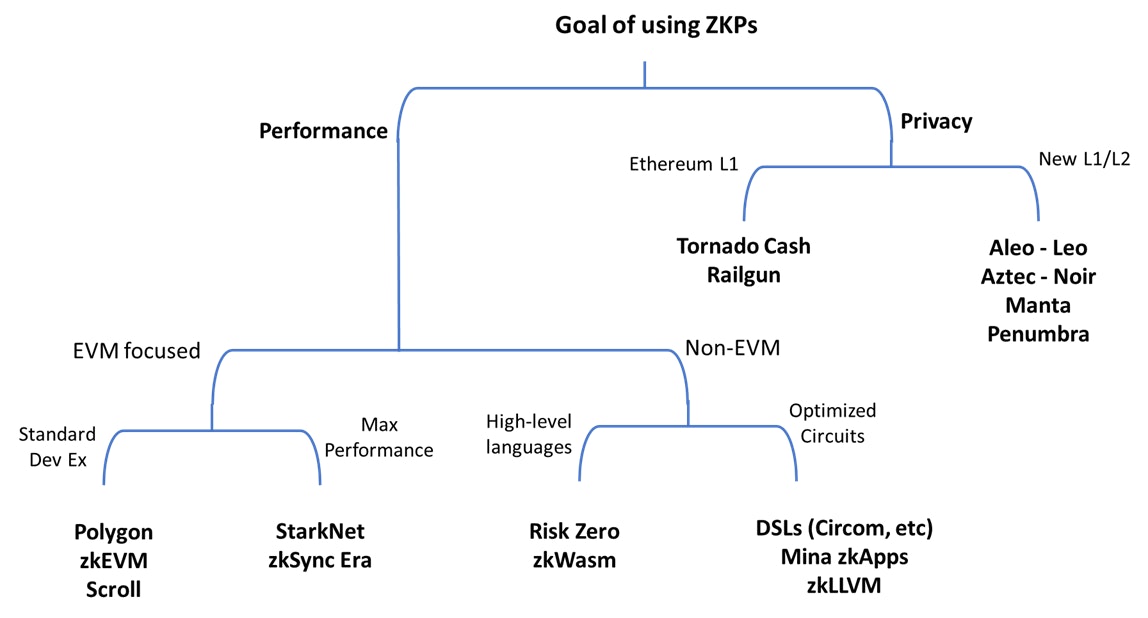
Performance-Focused zk applications
Developer can use ZKPs to achieve higher throughput (TPS) or lower fees by doing the bulk of application computing off-chain and only posting the proof on-chain. In this case, there are multiple frameworks to choose from. Each of these frameworks provides a flow to compile an application written in a high-level language to an equivalent representation called zk circuit that is suitable for proof generation. They provide a set of tools to compile the application code, generate the zk circuit, implement the zk prover, and generate the verifier code for the target ecosystem. We can divide these frameworks into two main buckets: EVM-focused and non-EVM.
EVM-focused zk Frameworks
This group of zk frameworks aligns with Ethereum by building on top of it as rollups. Transactions and applications are executed on the rollup’s zk virtual machine (zkVM). The proof is generated by a dedicated prover and posted to the L1 where it’s verified by a smart contract.
The first subset of this group implements zkVMs that are compatible with the EVM, hence, called zkEVM. The goal of these is to minimize friction by allowing Ethereum developers to use solidity and familiar tools such as Hardhat and Foundry without changes. They abstract the zk complexity by creating a circuit and prover that work for the EVM out-of-the-box. This bucket includes Polygon zkEVM and Scroll.
The second subset of this group is the zkVMs that are not natively EVM-compatible. Despite the incompatability, this group reduces friction by creating intermediate layers to allow developers to use Solidity. Vitalik calls this group type-4 zkEVM. zkSync Era and Starknet are good examples of this group. The advantage of using a Type-4 zkEVM is that it can offer higher throughput and lower fees than the EVM-compatible type. This makes them suitable for building high-throughput applications, such as on-chain games, or high-performance financial products such as order-book DEXs.
Building applications for type-4 zkEVM require more developer effort because there are limits on the Solidity code that can be used. Alternatively, developers can decide to learn a different language, e.g., Cairo, to develop native applications for these frameworks.
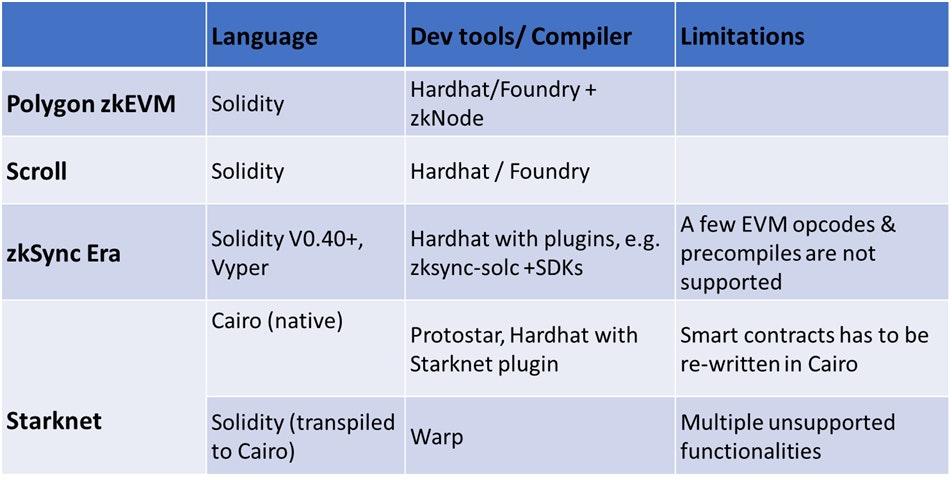
Sources: zkNode, Scroll, zksync-solc, zkSync SDKs, Protostar, Starknet Hardhat plugin, Warp
Non-EVM zk Frameworks
The other type of frameworks are those that don’t target the EVM architecture because they target competing L1s or general-purpose computing. Despite that, they still can be used to build application-specific zkRUs on Ethereum through specialized SDKs such as Sovereign.
There are two approaches here
- Developers write code in high-level languages that targets a specific VM architecture that is later compiled to a zk circuit.
- Developers write code using a domain specific language (DSL), e.g. Circom, that generates the zk circuit directly.
The former approach is more developer-friendly but often results in larger circuits that require longer proving time.
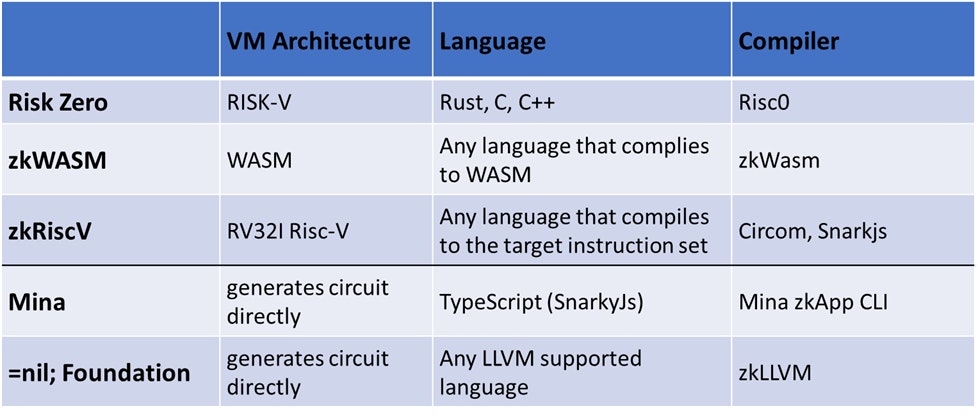
Sources: Risc0, zkWasm, Circom, Snarkjs, Mina zkApp CLI, zkLLVM
Privacy-focused zk applications
Using ZKPs to develop privacy-focused apps is often a more demanding task for developers. There has been less work toward using ZKPs to develop privacy-focused solutions when compared to scalability-focused ones making the learning curve steeper. The existing privacy applications have mainly focused on payment privacy and didn’t allow for much programmability. It’s a challenging task to combine privacy and programmability. Privacy focused applications follow one of two implementation options
- Building on top of a general-purpose L1
To enable private payment apps on L1s the ZKP logic needs to be built as a smart contract. The application often uses ZKPs to create private pools of capital. Users use these private pools as mixers to fund new wallets that are not linked to their original wallets. The famous example here is Tornado Cash. For these applications, proving is performed by the user and validation happens on chain. Hence, it’s critical to use ZKP systems that have fast proving, simple verification computations, and that doesn’t leak any of the user information in the generated proof.
As general-purpose chains are not optimized for the expensive cryptographic computations, the verification costs are often expensive for mainstream users limiting the adoption of these applications. The intuitive solution of moving the private-transaction application to a rollup to reduce gas costs can be challenging. In that scenario, the private transaction proof needs to be included in the rollup proof, i.e, proof recursion, which is not currently possible with general-purpose zk rollups on Ethereum.
2. Building a new L1/L2 focused on Privacy
To enable lower costs for private transactions and applications, developers are forced to either build a new privacy-forced L1, e.g. Manta Network and Penumbra, or a specialized rollup, e.g., Aztec. Most privacy-focused chains cannot yet support general-purpose computing and focus on specialized use cases. For instance, Penumbra and Renegade focus on private trading. Aleo is building a framework for private applications by creating the dedicated language Leo that complies programs written in a high-level language to the corresponding zk circuits. The application interactions are performed off-chain with only the proof posted as a private transaction on-chain. Aztec is moving in a similar direction but as an Ethereum L2. They recently announced their focus on creating a generalized private rollup that uses Noir as the default smart contract language.
zk Acceleration
After a developer selects the right zk development framework for their application and selects the underlying proving system, the following step is to optimize the performance of the application and find ways to improve user experience. This often boils down to improving the performance and latency of the prover. As discussed earlier, for rollups, reducing the prover time means shorter delay in submitting the proofs to the L1 and hence a shorter withdrawal delay. For user-generated proofs, i.e., privacy applications, faster proving means shorter transaction generation time and better UX.
As we have discussed in our previous article, accelerating the proving process often needs both software optimizations and dedicated hardware. In the past few months, the dedicated hardware competition has heated up with multiple companies entering the race. In this section, we discuss the current landscape of zk acceleration and how developers can benefit from that competition.
Proof as a service
The standard model of performing zk proving work so far have been to use powerful servers with multi-core CPUs and/or GPUs and utilizing optimized open-source libraries, e.g., Filecoin’s Bellperson, to improve the proving performance. This model adds operational complexity to the developers who need to maintain the proving infrastructure. A better model that addresses this complexity and allows for better specialization is the proof-as-a-service model. In this model, entities that need to generate proofs for a certain zk circuit or a certain use case connect to a provider who runs a proprietary software to perform the proving computations. Some companies can specialize in generating proofs for specific use cases. Axiom, for instance, has built a system that generates Halo 2 proofs for historical data on Ethereum. Other players can focus on specific ZKP backends, e.g., Plonk or Halo 2, and build proprietary optimizations that result in faster and more efficient computation of the proofs. =nil Foundation is taking this concept a step further by building a marketplace for ZKP computations. In this Proof Market, proof buyers submit bids to generate ZKPs that are matched and fulfilled by proof generators. Mina has a similar concept called the Snarketplace but it’s limited to the SNARK proofs needed for the Mina network.
Hardware Acceleration
With the launch of several L1s and rollups that depend on efficient generation of zk proofs, the competition to generate these proofs and earn the associated rewards will heat up. If these chains and L2 succeed to attract a significant user base, the proof generation can develop into an arms race that resembles the Bitcoin mining competition. There are different ZKP acceleration approaches, i.e., GPUs vs FPGA vs ASIC. This article from Amber Group does an excellent job in discussing these different options and the challenges that face each implementation option. However, in the long run, the companies that produce the most-efficient AISCs for proof generation will have significant economic advantage on the zk-focused chains.
It’s important to note that there is a major difference between zk proving competition and Bitcoin mining that is worth highlighting. In Bitcoin, the mining process was based on a simple computation, SHA256 hashing. This computation was fixed and not subject to change which focuses the competition around chip design innovation and access to the most-advanced semiconductor nodes. In the ZKP space, there is significant fragmentation between different proving protocols. Even with the same proving backend, e.g., Plonk, the target circuit size can lead to differences in ASIC performance. This distinction between Bitcoin mining and ZKP generation can lead to a situation with multiple winners each specializing in a different zk backend.
There are multiple players entering the field of zk-specific chips. Each player focuses on improving one of the two major operations of the proof generation: Multi-scalar multiplications (MSMs) and Number Theoretic Transform (NTT). The last player to come out of stealth was Cysic which announced its $6M seed round during ETH Denver. Cysic is focused on accelerating MSMs via the use of FPGAs. The flexibility of FPGAs can allow them to support different zk systems. This approach is similar to Ulventanna which announced a $15M seed round in January. Other players in the zk chip development space include Ingonyama, which released a library called Icicle that accelerates MSM and NTTs computations on GPUs, Accseal, Snarkify and Supranational. In addition to this list, there are other stealth companies and research efforts from reputable players in the Web 3 space. Examples of the latter include the CycloneMSM implementation from Jump Crypto to accelerate MSM computations using FPGA and Jane Street’s FPGA implementation to accelerate MSM and NTT.
Because of the increasing importance of ZKP acceleration and need for a fair evaluation of different implementations, competitions such as ZPrize are becoming an important venue to push the space forward. The 2022 run of the competition has more than $4M in awarded prizes.
Useful Educational Resources
In this section, we combine a list of educational resources that help builders get introduced to the ZKP space. This is by no means an exhaustive list as there is a lot of great content on topic. Comprehensive lists of zk resources can be found here and here. This is an effort to establish a friendly way for developers to learn about the space.
For those interested to understand the basics of ZKPs and how they work one of the first resources to check is zk Whiteboard Sessions from zk Hack. In particular, the three introductory sessions by Dan Boneh are high-level enough for anyone with some basic math understanding. The rest of the series addresses specific topics in the space.
For developers who want to jump straight into using zk tools, this excellent beginners guide comes in handy. After that, Poseidon Labs has created an Applied zk workshop that walks the developer through building a zk app using Circom and Hardhat. Other workshops that target other zk language and frameworks include this workshop using Noir and this one using Risc Zero.
Conclusion
As believers in the potential of ZKPs, Alliance strives to help more builders enter the space and to support them with funding and mentorship. In Web 3, ZKPs are already tackling the scalability and privacy pain points that hinder mainstream adoption. In Web 2, ZKPs can bring the ethos of trust minimization to a wide scope of businesses including SaaS, insurance, and credit scoring. This article is an effort to help builders integrate ZKPs into their products. The article walks builders through the different phases of planning ZKP integration, covering implementation options, and performance improvement post-deployment.
We encourage builders to reach out for further discussion and review the startup ideas in the ZKP space.
The authors would like to thank Shumo Chu, Anish Mohammed, members of the O(1) Labs for the fruitful discussions and their feedback on this article.
More to Read
Before It Was Obvious

Imran Khan
·Jun 18
You're sitting in front of your computer and you want to build a startup. You've seen Cursor sell to Elon for $60B . Maybe the previous generation was Mark Zuckerberg or Evan Spiegel. You look at these founders and compare yourself to them. They don't seem that much smarter than you. Their resumes aren't better than yours.
Yamanaka Factors: How Four Proteins Could Rewind Aging

Qiao Wang
·Jun 2
For most of the last century, biologists treated aging the way a mechanic treats an old car. Parts wear out, damage piles up, and the slow rusting eventually stops the engine. Under this view, aging runs in one direction. Biology has no reverse gear.
Finding Unlikely Allies

Will Robinson
·Apr 28
When Founders build on top of someone else's platform, they can activate a network of allies they could never have afforded to recruit.