Your Moat Isn't Your AI Prompt. It's Your Evaluations

Mohamed Elseidy
·Jun 17, 2025
At Alliance @alliancedao, we internally build various AI workflows that maximize and boost our operational efficiency. What started as simple prompts are now full fledged workflows that we highly rely on for our operations. With time, the scale and accuracy of our workflows have become more critical. We needed a more concrete infrastructure in place that systematically evaluates the performance of our workflows and gives us confidence in our operations.
Similarly, we figured out that this is largely true for any AI startup. While everyone is trying to find the perfect prompt, the real competitive advantage lies in building evaluation systems that capture why your AI works and how to make it continuously better.
Anyone can copy a prompt, but they can't replicate the months of iterative learning, the domain knowledge and the edge cases discovered through real user interactions, and the systematic evaluation framework that guided every prompt tweaking decision.
Consider what happens when AI companies do fund raising. Due diligence doesn't focus on the prompts themselves, rather, investors want to see the evaluation infrastructure that proves the system works reliably at scale. They're looking for evidence of systematic improvement, not just a demo that works on a few examples. The real moat lies in the accumulated knowledge about what works, what fails, and why.
In this article, I will discuss To illustrate how this evaluation-driven approach works in practice, let's follow an AI healthcare startup trying to athe main development cycle for building a robust AI evaluation system. utomate medical code extraction.
To give some context about the application, medical coding translates healthcare diagnoses, procedures, and services into standardized alphanumeric codes for billing and insurance claims. When a doctor writes "Patient presents with chest pain, administered EKG" a medical coder/specialist must convert this into specific codes like "R06.02" for chest pain and "93000" for EKG procedure. These codes determine whether hospitals get paid, and if they assign the wrong code, they might get exposed to legal and financial vulnerabilities. This process currently requires trained specialists who manually read physician notes, but AI systems could potentially automate this labor-intensive workflow while potentially improving accuracy and speed.
What Are AI Evaluations?
An evaluation (eval) is an automated test that measures how well your AI system performs on specific inputs/tasks. Think of it like unit tests for software, but instead of testing code logic, you're testing AI behavior and output quality.
Here are some eval examples for our medical coding application:
- Simple evals: These test basic factual accuracy, whether the AI extracted the correct information. This is similar to unit tests. An example would be: Does the AI extract "R06.02" when the correct chest pain code is "R06.02"? (Pass/Fail)
- Complex evals: These test whether AI outputs make logical sense together, in par with integration or end-to-end tests in software engineering. For example: Does the AI assign codes that make medical sense together, like not billing for both a new patient visit and follow-up visit on the same day?
- Business evals: These test whether AI outputs will work in the real world. Example: Will insurance actually pay claims with these code combinations?
There are many other types of evals (safety, robustness, alignment, performance, etc) that can be added depending on your team's assessment and specific business needs. In practice, evals are implemented as:
- Automated checks that run instantly on thousands of examples without human intervention. Note that you typically want many of these with high coverage.
- Expert reviews which represent manual assessments by domain experts for subjective criteria, e.g., clinical reasoning or appropriateness. Note that you typically use expert review for scenarios that are highly contentious or when the AI can't answer with high confidence.
- Production monitoring that tracks real business outcomes like claim approval rates, customer satisfaction, or revenue impact.
Understanding these evaluation types reveals why they're essential for any serious AI development effort.
Why Evals Are Critical
Building AI systems without systematic evaluation is fundamentally flawed. You're making decisions based on incomplete information, optimizing for metrics that might not matter, and deploying systems whose behavior you can't predict or control. The main drawbacks of an AI workflow without evals can be summarized as follows:
- Unpredictable performance: You don’t know how your AI will behave on new data or edge cases that weren't in your test set
- Blind optimization: Every prompt change, model update, or system modification is essentially a guess. You might improve one aspect while breaking others
- Silent degradation: AI performance quietly degrades over time as patterns shift, data distributions change, or underlying models get updated
- Scaling impossibility: You can't confidently handle new use cases, or different domains without systematic measurement of what works and what doesn't
On the other hand, evaluation-driven development solves these fundamental problems by creating systematic advantages that compound over time:
- Knowledge compounding: Every user interaction, edge case, and expert judgment gets encoded into your evaluation framework, giving you confidence in how your system behaves on new data.
- Systematic improvement: Instead of random prompt tweaking, every change is guided by data and measurement. You know exactly what works, what doesn't, and why.
- Scaling domain expertise: Once expert judgment is encoded in evals, you can detect and respond to performance changes immediately across unlimited cases.
- Competitive separation: While competitors struggle with basic functionality, your eval-driven system continuously improves through production usage, making new use cases and domains approachable.
Now that you understand what evals are and why they matter, here's how to build them systematically into your development process.
Evaluation Driven Development
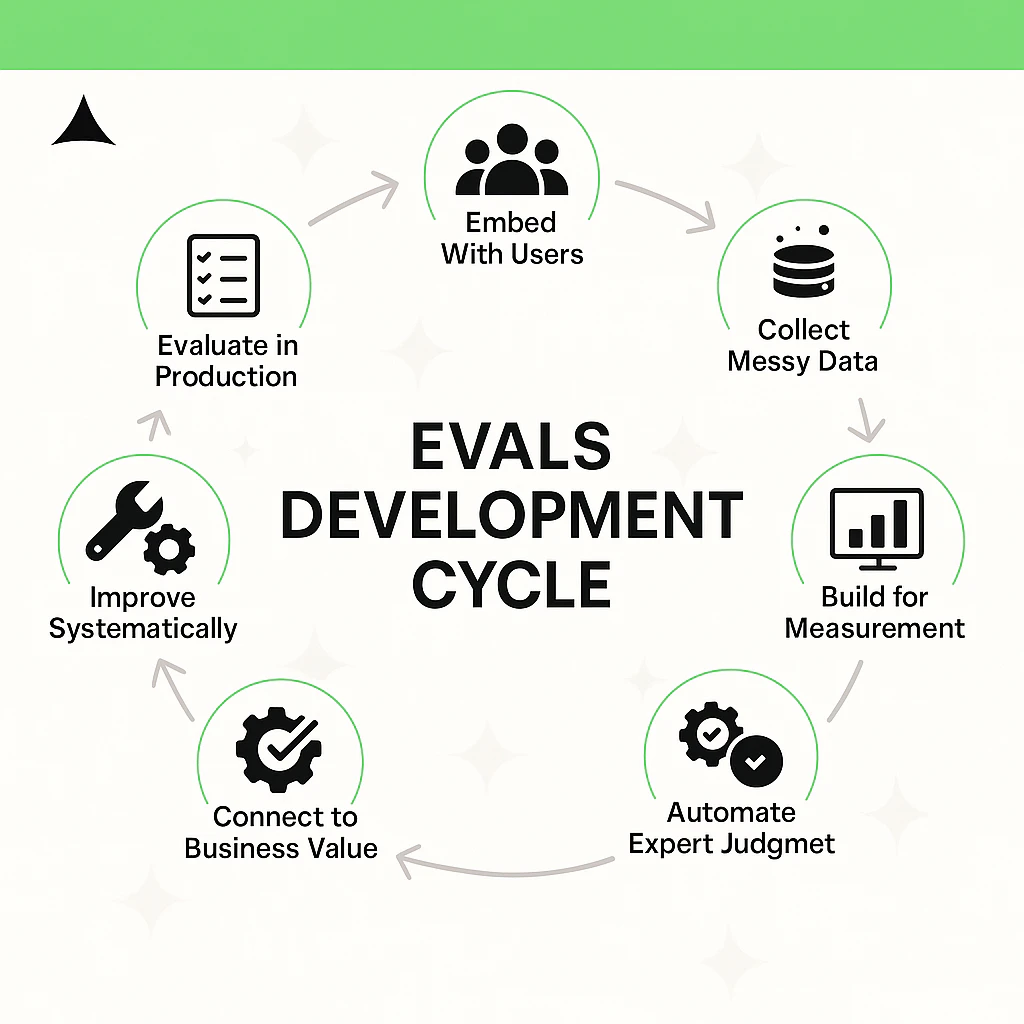
The following seven step cycle transforms AI startups into production ready systems with competitive moats. Whether you are building medical coding, legal analysis, financial forecasting, or any other domain-specific AI, this framework applies to a wide variety of applications.
1. Embed With Users
The first step is becoming embedded in your end-user's actual workflow. This isn't about conducting interviews or sending surveys, it's about sitting next to users and observing how they make decisions in real-time. You need to understand not just what they do, but why they do it, what edge cases they encounter, and how they handle ambiguous situations
This embedding process reveals the gap between official procedures and actual practice. Users often develop informal workarounds, shortcuts, and judgment calls that aren't documented anywhere but are crucial for getting work done effectively. These hidden insights become the foundation of your evaluation framework
The key insight is that understanding the problem at hand never stops. Throughout development, ongoing conversations with domain experts continue to refine your understanding of what actually matters versus what might seem important.
Our healthcare startup example would spend their first month shadowing medical coders at different hospitals, observing how they distinguished between similar diagnoses, which procedure codes required specific evidence, and when they escalated complex cases to the specialists. This would reveal that coders weren't just following rules, rather, they were making judgment calls based on years of experience with insurance requirements and clinical logic.
2. Collect Messy Data
Most AI teams start with clean, representative datasets that look good at start but fail in production. Real world data is messy, incomplete, and full of edge cases that break your assumptions about how the system should work. Alternatively, you need to actively seek out the difficult cases, the data that makes your current system fail. This means going beyond the simple examples and collecting scenarios where even domain experts disagree or need additional context to make decisions.
That being said, it is more important to organize your data strategically: separate sets for development, evaluation, edge case exploration, and "golden" examples reviewed by multiple experts. This structure ensures you can measure progress objectively while continuously expanding your understanding of the problem space. Begin with 100-200 examples split 60/30/10 across development, evaluation, and holdout sets.
In our medical coding case, the team might initially collect straightforward family medicine cases that yield high accuracy scores, only to discover failure on emergency room notes with missing information or complex procedures requiring multiple billing codes. So they expand their training datasets to incorporate these edge cases into their problem space.
3. Build for Measurement
As David Knuth stated before: “Premature optimization is the root of all evil”. Resist the urge to build the perfect system immediately. Your goal is creating the simplest possible end-to-end system that accepts real inputs and produces measurable outputs. This V0 system will likely perform poorly, but that's exactly what you want, i.e., a clear baseline for systematic improvement
Focus on the measurement infrastructure over performance optimization. You need systems that can process inputs, generate outputs, and evaluate results consistently across thousands of test cases. The ability to measure reliably is more valuable than any individual performance gain. This approach forces you to define success criteria explicitly and creates feedback loops that guide all future development decisions.
You can use AI tracing and evaluation frameworks like Langfuse or Phoenix, and set up automated runs on every model or prompt change with dashboard tracking and alerts when scores drop.
In the healthcare startup example, they would start with building basic components for parsing clinical notes and assigning billing codes, using simple prompts with no fancy engineering. Results will likely be mediocre, but this builds a baseline for a measurable system that can be improved systematically.
4. Automate Expert Judgment
This is where evaluation driven development becomes powerful. Converting the human expertise you observed into automated graders that can run at scale. You're essentially encoding years of domain knowledge into systems that can evaluate thousands of outputs consistently.
When building these automated graders, follow these core guidelines to ensure your evals are effective and drive real improvements. Each guideline includes implementation approaches that range from simple rule-based code to sophisticated LLM judges (using AI to evaluate AI outputs), depending on the complexity of what you're evaluating:
1. Be Specific and Measurable:
- Bad: "Does the output look reasonable?" ~ subjective
- Good: "Does the output contain all required fields with valid formats?"
- Example: "Does the output include exactly one primary diagnosis code in ICD-10 format?"
- Implementation: Simple code check using regex pattern matching
- Test Business Logic:
- Bad: "Is the AI smart?" ~ subjective
- Good: "When facing ambiguous inputs, does the AI flag for human review instead of guessing?"
- Example: "When clinical notes are incomplete, does the system request additional documentation rather than assigning default codes?"
- Implementation: LLM-as-a-judge to assess reasoning and decision-making
- Reproducible Results:
- Bad: Subjective scoring that varies between reviewers
- Good: Clear pass/fail criteria that anyone can apply consistently
- Example: "Does the code match the documented condition? (Yes/No)"
- Implementation: Either rule-based matching or LLM judge with clear criteria
- Focus on Failure Modes:
- Bad: Only testing easy path scenarios
- Good: Deliberately testing edge cases where the system is likely to break
- Example: Test with illegible handwriting, unclear voice notes, multiple conditions, and contradictory symptoms
- Implementation: Curated test dataset with LLM judges for complex scenario assessment
The key is to capture the actual decision making process used by your target users, including all the subtle exceptions and edge cases that distinguish expert judgment from rule following.
5. Connect to Business Value
Technical metrics without business context are meaningless. You need direct connections between evaluation scores and financial outcomes through quantified business models. Understanding the cost structure helps prioritize which evaluations matter most. Some improvements might look impressive technically but dont have much business impact, while small gains in other areas could translate to large value. This business model guides every engineering decision about where to invest effort and helps you avoid optimizing metrics that don't drive user outcomes.
In our medical coding example, analysis might reveal that manual coding costs several dollars per encounter, while incorrect diagnosis codes cause significant claim denials. This means improving accuracy by just a few percentage points could translate to large business benefits.
6. Improve Systematically
With a robust evaluation infrastructure, improvement becomes systematic rather than random trial & error. Each evaluation cycle reveals the highest impact problems to solve next, and then you can measure the effect of every change objectively
Follow a progression from basic functionality to sophisticated edge case handling. Early stages focus on fundamental gaps, mid stages add business logic and consistency checks, and advanced stages implement confidence based routing for complex cases. Every improvement cycle should be guided by evaluation data, not intuition. Teams then know exactly which problems to solve next and can measure systematic progress over time.
For example, in our healthcare startup example, basic graders might reveal struggles with surgical procedures, leading to targeted improvements in that area before expanding to other areas.
7. Evaluate in Production
Production usage always reveals gaps that no amount of pre launch testing can catch. You will need a continuous evaluation framework that monitors performance on live data and identifies emerging issues. Implement quality monitoring, regular expert review of sample cases, and systematic expansion of coverage as you encounter new edge cases. This creates a feedback loop that continuously improves both your system and your evaluation framework.
Conclusion
The real competitive moat in AI isn't your prompt engineering or model selection. It's the systematic understanding of what works in your specific domain and why. Evaluation driven development transforms that understanding from tribal knowledge into competitive infrastructure. Each evaluation captures judgment calls, edge cases, and domain expertise that takes years to develop and can't be easily reverse engineered by competitors.
If you are working on an interesting startup idea, don’t hesitate to contact us and apply to Alliance.
More to Read
Before It Was Obvious

Imran Khan
·Jun 18
You're sitting in front of your computer and you want to build a startup. You've seen Cursor sell to Elon for $60B . Maybe the previous generation was Mark Zuckerberg or Evan Spiegel. You look at these founders and compare yourself to them. They don't seem that much smarter than you. Their resumes aren't better than yours.
Yamanaka Factors: How Four Proteins Could Rewind Aging

Qiao Wang
·Jun 2
For most of the last century, biologists treated aging the way a mechanic treats an old car. Parts wear out, damage piles up, and the slow rusting eventually stops the engine. Under this view, aging runs in one direction. Biology has no reverse gear.
Finding Unlikely Allies

Will Robinson
·Apr 28
When Founders build on top of someone else's platform, they can activate a network of allies they could never have afforded to recruit.